



La UNIA cierra en La Rábida unos Cursos de Verano con récord de asistencia
La Universidad Internacional de Andalucía ha cerrado esta semana su Cursos de Verano en la Sede de La Rábida marcando un nuevo máximo de asistencia. Cerca de 600 alumnos se han matriculado en las 15 actividades desarrolladas entre el 7 y el 23 de julio, con una media de 39 estudiantes por actividad. El Salvador ha aportado el grupo extranjero más numeroso, de un colectivo que ha tenido a doce países representados.
La oferta ha combinado 10 cursos y 5 encuentros de verano con temáticas que han ido del hidrógeno verde y las energías renovables, a Doñana, la novela histórica, la Atlántida y el Megalítico, la gastronomía, la relación puerto-ciudad, la salud, la contratación pública o las bellas artes iberoamericanas, además de la inteligencia artificial asociada a la educación, la empresa y las finanzas.
Para María de la O Barroso, directora de la Sede de La Rábida, esta 83 edición de los Cursos de Verano “ha sido un éxito, gracias a los temas pero, sobre todo, a que mantienen su esencia año tras año, como es la convivencia, el diálogo, la apertura a nuevas ideas y, por supuesto, el conectar con los gustos e intereses personales en un entorno donde, siglos después, se sigue respirando el espíritu iberoamericano”.
Balance de cursos
Del total de matriculados, 304 han sido hombres (52,7%) y 273 mujeres (47,3%). Casi el 20% de los inscritosen esta edición han sido beneficiarios del programa de becas, que la Universidad Internacional de Andalucía convoca con el apoyo de la Fundación Unicaja.
Si bien el estudiante nacional es mayoría en esta programación estival, esta edición ha contado con representantes de otras doce nacionalidades. Así, además de El Salvador, entre los países de origen de los matriculados están Francia, México, Cuba, Colombia, Italia, Paraguay, Venezuela, Argentina, Ecuador, Perú y Japón.
Entre el profesorado de esta edición han pasado por La Rábida nombres como Andrés Úbeda de los Cobos, jefe de Conservación de Pintura del siglo XVIII y Goya del Museo del Prado; María Concepción Ordiz Fuertes, presidenta del Tribunal Administrativo Central de Recursos Contractuales; el poeta y filósofo Jorge Riechmann; la eurodiputada Teresa Jiménez Becerril; la catedrática de Prehistoria Primitiva Bueno, el directivo de Sanvik Mining Enrique Mota o Mikel Landabaso, director del Joint Research Centre (JRC) de la Comisión Europea en Sevilla.
,La provincia de Huelva se ha posicionado en el centro de la estrategia nacional para la descarbonización industrial mediante el impulso de tecnologías limpias, el aprovechamiento del CO2 biogénico y el desarrollo de recursos renovables autóctonos. Así lo ha manifestado José Antonio Agüera, director de Magnon Green Energy, durante su intervención en Energías renovables y Huelva. Un curso de verano organizado en la Sede de La Rábida por la Universidad Internacional de Andalucía, en colaboración con Magon y Naturgy, donde se ha analizado el impacto socioeconómico y tecnológico de las nuevas fuentes sostenibles dentro del tejido productivo andaluz.
Para el especialista, el escenario actual representa un punto de inflexión decisivo para el desarrollo industrial regional. «Los principales vectores de la transición energética se están dando en la provincia de Huelva», ha aseverado Agüera, subrayando que están marcando el camino que tienen que seguir los demás. A su juicio, Huelva afronta «una nueva revolución local, comparable a la que transformó la provincia en los años 60 y 70», gracias a que reúne una «oportunidad local» respaldada por disponibilidad de espacio, sol e información técnica. El objetivo prioritario, según el directivo, pasa por «aprovechar estas posibilidades para generar crecimiento y fomentar el asentamiento de las personas en el territorio».
Durante su intervención, el responsable de Magnon Green Energy ha puesto en valor el papel del CO2 biogénico -el resultante de la combustión de biomasa renovable- y la estabilidad operativa que ofrece esta fuente limpia en comparación con alternativas como la energía solar o eólica. «Su principal ventaja es que se trabaja a nivel muy local, lo que permite que toda su cadena de valor se cree en la zona de producción de la biomasa», ha explicado Agüera, haciendo hincapié en que se trata de una fuente «capaz de ofrecer gestión y capacidad, lo que la convierte en una energía muy controlada».
Respecto a los retos que afronta el sector para la captación y aprovechamiento industrial del carbono, el experto ha descartado cuellos de botella en el ámbito tecnológico. «No existen barreras tecnológicas, sino más bien necesidades de infraestructura eléctrica», ha remarcado, detallando que aunque la captura de CO2 es ya una realidad, «transformarlo en moléculas de mayor valor para la industria química sí que se necesita generación de hidrógeno e infraestructura eléctrica, siendo esta la principal preocupación actual».
Finalmente, Agüera ha ratificado la importancia de los encuentros universitarios para conectar los avances industriales con la ciudadanía. La alianza entre la universidad y el tejido productivo resulta «fundamental porque estos foros permiten abrir debates, clarificar puntos de vista y generar conversaciones constructivas», ha concluido, destacando que las aulas de la UNIA ofrecen el entorno propicio para trasladar a la sociedad cómo se está ejecutando esta transformación.
Cursos de Verano
José Antonio Agüera es ponente del curso de verano Energías renovables y Huelva organizado en la Sede de La Rábida por la Universidad Internacional de Andalucía del 20 al 23 de julio. Este curso de verano aborda la transición energética desde una perspectiva integral y aplicada al territorio de Huelva, donde se han abordado los cambios en el modelo energético actual, los retos ambientales, económicos y sociales, además de una reflexión crítica sobre el futuro energético de la provincia, sensibilizando sobre la importancia de las renovables y la sostenibilidad.
Más información: https://www.unia.es/estudios-y-acceso/oferta-academica/cursos-de-verano/energias-renovables-y-huelva#plan-de-estudio-y-calendario
,La distribución de los minerales en la corteza terrestre no es uniforme. Procesos como la actividad magmática, la circulación de fluidos, la sedimentación o la alteración superficial pueden concentrarlos en determinadas zonas y dar lugar a yacimientos minerales.
En este artículo explicamos qué son, cómo se forman, qué tipos existen y dónde se localizan algunos de los principales yacimientos minerales de España.
Qué es un yacimiento mineral
Un yacimiento mineral es una concentración natural de una o varias sustancias minerales originada por procesos geológicos y localizada en una zona concreta de la corteza terrestre. Se diferencia de las rocas que lo rodean por presentar una mayor proporción de determinados minerales o elementos, así como unas características propias de forma, extensión y composición.
Sin embargo, la presencia de una concentración mineral no significa que pueda explotarse. Para determinar su posible aprovechamiento es necesario conocer la cantidad y calidad del material, la continuidad de la mineralización, su profundidad y las técnicas necesarias para extraerlo y tratarlo. También influyen factores económicos, ambientales, legales y sociales, que pueden variar con el tiempo.
Por tanto, un yacimiento puede tener interés geológico sin resultar técnica o económicamente viable como explotación minera. Esta viabilidad sólo puede establecerse después de realizar trabajos de exploración, caracterización y evaluación.
Diferencia entre yacimiento mineral y mina
Un yacimiento mineral es una formación geológica natural, mientras que una mina es la explotación creada para extraer y tratar sus materiales. No todos los yacimientos llegan a convertirse en minas, ya que su aprovechamiento debe resultar viable desde el punto de vista técnico, económico, ambiental y legal.
Mena, ganga, ley mineral y ley de corte
Para analizar la composición y el posible aprovechamiento de un yacimiento se utilizan varios conceptos básicos:
- La mena es el mineral o conjunto de minerales que contiene la sustancia de interés que se pretende recuperar.
- La ganga está formada por los minerales y materiales que acompañan a la mena, pero que no tienen interés económico en las condiciones consideradas.
- La ley mineral indica la concentración del elemento o sustancia aprovechable presente en una muestra o cuerpo mineralizado. Puede expresarse, por ejemplo, en porcentaje o en gramos por tonelada.
- La ley de corte es el valor mínimo de concentración utilizado para diferenciar el material que puede procesarse del que queda fuera del aprovechamiento en unas condiciones determinadas.
La ley de corte no es un valor fijo. Puede variar según los costes de extracción y tratamiento, la tecnología disponible, el precio de la materia prima y otros factores técnicos, económicos y ambientales.
Cómo se produce la formación de yacimientos minerales
La formación de yacimientos minerales ocurre cuando determinados procesos geológicos movilizan y concentran elementos que normalmente se encuentran dispersos en las rocas. Para ello debe existir una fuente de materiales, un mecanismo capaz de transportarlos y unas condiciones favorables para que se acumulen.
El transporte puede producirse mediante magmas, fluidos hidrotermales, aguas superficiales o subterráneas, así como por procesos de erosión y sedimentación. Los minerales se concentran cuando cambian la temperatura, la presión o la composición química del medio, o mediante fenómenos como la cristalización, la precipitación y la evaporación.
Las fallas, fracturas, contactos entre rocas, capas permeables y cuencas sedimentarias pueden favorecer el movimiento y depósito de los materiales. Por ello, los yacimientos minerales no se distribuyen de forma aleatoria, sino que están asociados a contextos geológicos determinados.
Principales tipos de yacimientos minerales
Los yacimientos minerales pueden clasificarse según su forma, las sustancias que contienen o los procesos responsables de su origen. Una de las clasificaciones más útiles es la genética, que los agrupa de acuerdo con los procesos geológicos que concentraron los minerales.
Según este criterio, se distinguen yacimientos magmáticos y pegmatíticos, hidrotermales, sedimentarios y volcanosedimentarios, metamórficos, supergénicos y residuales, y de placer. No obstante, algunos depósitos pueden haber sido originados o modificados por varios procesos sucesivos.
Yacimientos magmáticos y pegmatíticos
Los yacimientos magmáticos se forman durante el enfriamiento y la cristalización del magma. A medida que los minerales cristalizan, determinados elementos pueden separarse del material fundido y concentrarse en zonas concretas. Estos procesos pueden originar depósitos de cromita, magnetita o sulfuros de níquel y cobre.
Los yacimientos pegmatíticos se desarrollan en las fases finales de la evolución de algunos magmas. Los materiales residuales se enriquecen en agua, gases y elementos que no se incorporaron a los primeros minerales cristalizados, dando lugar a pegmatitas que pueden contener litio, estaño, tántalo o tierras raras.
Yacimientos hidrotermales
Los yacimientos hidrotermales se originan por la circulación de fluidos calientes a través de los poros, fracturas y fallas de las rocas. Estos fluidos transportan sustancias minerales que precipitan ante cambios de temperatura, presión o composición química.
Las mineralizaciones pueden adoptar formas como vetas, filones, reemplazamientos o redes de pequeñas fracturas. Los procesos hidrotermales intervienen en numerosos depósitos de cobre, plomo, zinc, oro, plata, estaño, wolframio, fluorita o barita.
Yacimientos sedimentarios y volcanosedimentarios
Los yacimientos sedimentarios se forman en la superficie terrestre o cerca de ella mediante procesos de erosión, transporte, sedimentación y precipitación de sustancias disueltas.
Los yacimientos volcanosedimentarios aparecen en ambientes donde coinciden la actividad volcánica y la sedimentación. En algunos casos, los fluidos hidrotermales transportan metales hasta el fondo marino, donde precipitan y forman acumulaciones de sulfuros de cobre, zinc y plomo.
Yacimientos asociados a procesos metamórficos
El metamorfismo transforma las rocas cuando quedan sometidas a cambios de presión y temperatura sin llegar a fundirse por completo. Durante este proceso pueden formarse nuevos minerales o movilizarse sustancias que ya estaban presentes en la roca.
Se distingue entre yacimientos metamórficos, generados por el propio metamorfismo, y yacimientos metamorfizados, que ya existían y posteriormente fueron deformados o modificados.
Yacimientos supergénicos y residuales
Los yacimientos supergénicos se forman cerca de la superficie por la alteración de rocas o depósitos preexistentes. El agua y el oxígeno disuelven algunos minerales, cuyos componentes pueden desplazarse y volver a precipitar a mayor profundidad.
En los yacimientos residuales, la meteorización elimina los componentes más solubles de la roca y deja concentrados los minerales menos móviles. Este proceso puede originar depósitos de bauxita, hierro o níquel laterítico.
Yacimientos de placer
Los yacimientos de placer se forman cuando la erosión libera minerales de una roca o depósito preexistente y estos son transportados y concentrados por procesos mecánicos.
Los minerales más densos y resistentes tienden a acumularse en cauces fluviales, terrazas o playas. Entre los materiales que pueden aparecer en estos depósitos se encuentran el oro, el platino, la casiterita, la ilmenita y el rutilo.
Cómo se evalúa un yacimiento mineral
La evaluación de un yacimiento permite determinar sus dimensiones, la cantidad y calidad de los materiales que contiene y las condiciones necesarias para su posible aprovechamiento. Para ello se combinan trabajos de campo, cartografía geológica, métodos geofísicos y geoquímicos, muestreos, análisis de laboratorio, sondeos y modelos tridimensionales del subsuelo.
Caracterización del yacimiento y estimación de recursos
La caracterización permite obtener información sobre:
- La forma, extensión, profundidad y continuidad de la mineralización.
- El volumen y la densidad de los materiales.
- La concentración o ley de los minerales de interés.
- La composición mineralógica de las rocas.
- La calidad de los datos y su grado de incertidumbre.
A partir de esta información se construyen modelos geológicos y se estima la cantidad de material que puede constituir un recurso mineral.
Un recurso mineral no equivale automáticamente a una reserva. Para que una parte del recurso pueda clasificarse como reserva debe demostrarse que puede extraerse de manera económicamente viable tras aplicar los estudios y factores correspondientes.
Viabilidad técnica, económica y ambiental
La posible explotación de un yacimiento depende de factores como:
- El método de extracción y las condiciones del terreno.
- Los procesos necesarios para recuperar los minerales.
- Los costes de construcción, extracción, tratamiento y transporte.
- El precio y la demanda de la materia prima.
- La disponibilidad de agua, energía e infraestructuras.
- La gestión de residuos, estériles y aguas mineras.
- Los posibles impactos sobre el suelo, el agua, el aire, los ecosistemas y el paisaje.
- Las autorizaciones y la normativa aplicable.
Estos factores pueden cambiar con el tiempo. Por ello, la evaluación de un yacimiento es un proceso multidisciplinar sujeto a revisiones periódicas.
Principales yacimientos minerales en España
España cuenta con una gran diversidad de yacimientos minerales vinculados a su compleja historia geológica. Los procesos magmáticos, hidrotermales, sedimentarios, metamórficos y de alteración superficial han favorecido la formación de depósitos con cobre, plomo, zinc, mercurio, hierro, estaño, wolframio, litio y otros recursos.
Su distribución no es uniforme, sino que depende de las características geológicas de cada zona.
Mapa de los principales yacimientos minerales de España
Este mapa muestra la localización aproximada de algunos de los principales yacimientos y distritos minerales de España. La selección incluye depósitos de mercurio, wolframio, estaño, tántalo, zinc, plomo, cobre y níquel vinculados a diferentes procesos geológicos.
No representa todos los yacimientos e indicios existentes en el país, sino una muestra orientativa de su diversidad geológica y minera.
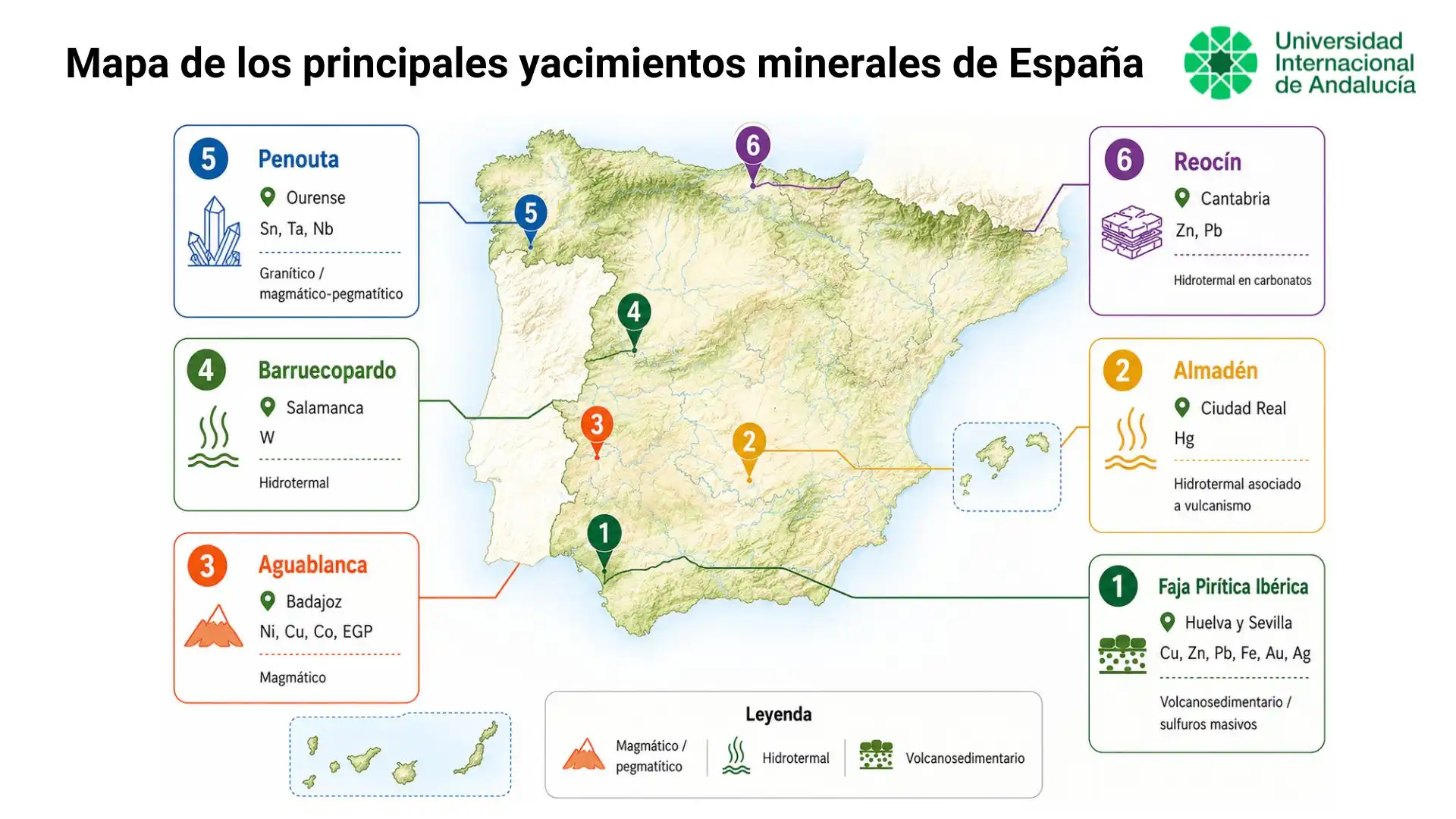
Nº EN EL MAPA YACIMIENTO O DISTRITO MINERALES PRINCIPALES TIPO DE YACIMIENTO LOCALIZACIÓN 1 Faja Pirítica Ibérica Cu, Zn, Pb, Fe, Au, Ag Volcanosedimentario / Sulfuros masivos Huelva y Sevilla (Andalucía) 2 Almadén Hg Hidrotermal asociado a vulcanismo Ciudad Real (Castilla La Mancha) 3 Aguablanca Ni, Cu, Co, EGP Magmático Badajoz (Extremadura) 4 Barruecopardo W Hidrotermal Salamanca (Castilla y León) 5 Penouta Sn, Ta, Nb Granítico / magmático - pegmatítico Ourense (Galicia) 6 Reocín Zn, Pb Hidrotermal en carbonatos Cantabria
Ejemplos destacados de yacimientos minerales en España
Los ejemplos seleccionados muestran la variedad geológica de los yacimientos minerales en España:
- Faja Pirítica Ibérica: situada principalmente en Huelva y Sevilla, reúne importantes depósitos de sulfuros masivos con cobre, zinc, plomo, oro y plata.
- Almadén: localizado en Ciudad Real, es un referente geológico e histórico por sus mineralizaciones de mercurio.
- Aguablanca: en Badajoz, es un yacimiento magmático de níquel y cobre, con cobalto y elementos del grupo del platino.
- Barruecopardo: en Salamanca, destaca por su mineralización de wolframio asociada a filones hidrotermales.
- Penouta: en Ourense, presenta mineralizaciones de estaño, tántalo y niobio vinculadas a un granito especializado.
- Reocín: en Cantabria, es un yacimiento de zinc y plomo alojado en rocas carbonatadas.
Esta selección no es exhaustiva, pero permite observar la diversidad de minerales y procesos geológicos presentes en el territorio español.
Importancia y gestión sostenible de los recursos minerales
Los yacimientos minerales suministran materias primas necesarias para la construcción, la industria, las comunicaciones, la generación de energía y numerosas tecnologías de uso cotidiano.
Sin embargo, su aprovechamiento también puede implicar consumo de agua y energía, generación de residuos y alteraciones del territorio. Por ello, debe acompañarse de medidas de prevención, control y restauración ambiental.
Yacimientos y minerales críticos para la transición energética
Algunos yacimientos contienen materias primas consideradas críticas por su importancia económica y por los riesgos asociados a su suministro. Minerales como el cobre, el litio, el níquel, el cobalto o las tierras raras intervienen en la fabricación de baterías, redes eléctricas, aerogeneradores y otras tecnologías vinculadas a la transición energética.
La exploración y evaluación de estos recursos debe combinar la seguridad del suministro con criterios ambientales y sociales. En el artículo sobre minerales críticos para la transición energética puedes conocer cuáles son los más relevantes y qué papel desempeñan en el desarrollo de tecnologías bajas en carbono.
Economía circular y aprovechamiento responsable de los minerales
La gestión sostenible de los recursos minerales no depende únicamente de la extracción de nuevos materiales. El reciclaje de metales, la recuperación de minerales presentes en residuos y la reutilización de determinados subproductos pueden reducir el consumo de materias primas y limitar la cantidad de desechos generados.
Estas medidas complementan la explotación de los yacimientos y favorecen un uso más eficiente de los recursos. El artículo sobre economía circular en minería explica cómo pueden aplicarse el reciclaje, la recuperación y la reutilización dentro de la actividad minera.
Cómo especializarse en geología y gestión ambiental de los recursos minerales
La especialización en recursos minerales requiere combinar conocimientos de mineralogía, petrología, geoquímica, geofísica y geología estructural con técnicas de exploración, evaluación y análisis ambiental.
También resulta fundamental manejar herramientas como los sistemas de información geográfica y la teledetección, además de comprender los riesgos y efectos asociados a la actividad minera.
El Máster Universitario en Geología y Gestión Ambiental de los Recursos Minerales, impartido conjuntamente por la UNIA y la Universidad de Huelva, ofrece una formación avanzada en estas áreas. Su plan de estudios permite orientar el aprendizaje hacia la geología, exploración y evaluación de los recursos minerales o hacia su análisis y gestión ambiental, con una orientación profesional o investigadora.
Esta formación está dirigida principalmente a titulados en Geología, Ingeniería Geológica, Ingeniería de Minas, Ciencias Ambientales y otras disciplinas afines que quieran profundizar en el estudio y la gestión sostenible de los recursos minerales.
Conoce el Máster Universitario en Geología y Gestión Ambiental de los Recursos Minerales
Preguntas frecuentes sobre los yacimientos minerales
- ¿Qué es un yacimiento mineral?
Es una concentración natural de minerales o elementos formada por procesos geológicos y localizada en una zona concreta de la corteza terrestre.
- ¿Cómo se forman los yacimientos minerales?
Se forman cuando procesos magmáticos, hidrotermales, sedimentarios, metamórficos o superficiales transportan y concentran determinados minerales en una zona.
- ¿Qué tipos de yacimientos minerales existen?
Según su origen geológico, pueden ser magmáticos, pegmatíticos, hidrotermales, sedimentarios, volcanosedimentarios, metamórficos, supergénicos, residuales o de placer.
- ¿Cuál es la diferencia entre un yacimiento mineral y una mina?
El yacimiento es la concentración geológica natural, mientras que la mina es la explotación creada para extraer y tratar sus materiales.
- ¿Dónde se encuentran los principales yacimientos minerales de España?
Se distribuyen por distintas zonas del país. Algunos ejemplos son la Faja Pirítica Ibérica, Almadén, Aguablanca, Barruecopardo, Penouta y Reocín.
Frente a la inmediatez digital y la adicción a las pantallas, es necesaria la pausa reflexiva que ofrece la cultura desde la métrica y la palabra. Así lo ha manifestado Jorge Riechmann, poeta y ensayista, durante su participación en el curso de verano Voces del extremo: poéticas de la contracultura organizado en la Sede de La Rábida de la Universidad Internacional de Andalucía para debatir el papel del lenguaje poético como resistencia social y ecológica.
«Necesitamos crear un espacio de silencio alrededor del verso y desengancharnos de la adicción a los algoritmos. La propia poesía propicia eso, creando un espacio donde pueden ocurrir cosas», ha planteado. A su juicio, la aparente complejidad o «resistencia» de ciertos textos no constituye una barrera, sino un «tropiezo» positivo que invita a volver a ellos en diferentes momentos vitales para activar la conciencia.
Cuestionado sobre la capacidad real de los versos para frenar la resignación colectiva, Riechmann ha matizado el alcance del arte, apelando a la responsabilidad social de la ciudadanía. «Los poemas pueden ayudarnos, pero no van a salvarnos por sí solos; para salvarnos necesitamos formas de coordinación, construcción de comunidad y acción colectiva hacia las cuales la poesía puede ayudarnos a avanzar», ha explicado.
Uno de los ejes de trabajo de Riechmann aborda la parálisis de la sociedad ante la crisis climática. «No se debe a la falta de datos, pues ya desde comienzos de los años 70 teníamos un buen diagnóstico científico. El problema apunta a una desconexión de nuestra verdadera condición terrestre», ha aseverado el poeta, remarcando que, si no se transforma la forma de vivir, producir y consumir, el porvenir se presenta «bastante negro».
En este sentido, ha matizado que la sociedad no se enfrenta a un problema aislado, sino a una «policrisis ecológico-social que requiere una transformación muy a fondo». Ante esta coyuntura, el ensayista sitúa a la literatura de la disidencia como una palanca para derribar los principales mitos del modelo actual.
«Uno de los tabúes más importantes es la separación con el resto del mundo y de la naturaleza. Existe una ilusión de que somos seres superiores o desconectados, cuando en realidad somos ecodependientes e interdependientes», ha argumentado Riechmann, defendiendo que el arte lírico facilita la tarea cultural de reconexión imprescindible para el cambio.
Cursos de Verano
Jorge Riechmann participa en el curso de verano Voces del extremo: poéticas de la contracultura organizado del 20 al 22 de julio en la Sede de La Rábida de la Universidad Internacional de Andalucía. Un encuentro que reúne arte, literatura, estética y medioambiente para un análisis crítico de la iconosfera actual, donde el arte y la estética inundan las vidas de los ciudadanos, sólo que convertidos en meros espectadores y consumidores de mercancías.
Más información: https://www.unia.es/estudios-y-acceso/oferta-academica/cursos-de-verano/voces-del-extremo-poeticas-de-la-contracultura
,La Universidad Internacional de Andalucía (UNIA) ha finalizado en la Sede Antonio Machado de Baeza (Jaén) la edición de 2026 de su Escuela de Teatro, dirigida por Nieves Pérez Abad, de la Escuela Superior de Arte Dramático (ESAD) de Murcia, y coordinada por César Oliva Bernal, de la Escuela Superior de Arte Dramático (ESAD) de Murcia y miembro del Actors Studio.
La directora de la Escuela de Teatro afirma que «se ha convertido en un espacio de referencia entre los cursos de verano de artes escénicas en España, gracias a sus más de veinte ediciones y a la continua actualización» y esto se debe a su oferta de «una formación y especialización en las distintas disciplinas teatrales con los/as profesionales de primera fila del sector».
En esta edición «han participado en total ochenta y tres estudiantes, procedentes de toda la geografía española, desde Galicia hasta Bilbao, Cataluña, Madrid, Valencia o Extremadura, por citar algunas de las comunidades autónomas de procedencia del alumnado», añade Nieves Pérez Abad.
Y señala que el estudiantado y el profesorado destacan «valores que hacen de esta Escuela de Teatro un entorno especial, y motivador: el carácter de punto de encuentro entre profesionales, estudiantes (la mayoría de Arte Dramático), personas con experiencia en el ámbito del teatro aficionado; y el alto nivel del profesorado participante, entre otros aspectos. El hecho de que estudiantes participen, año tras año, junto a los/as nuevos/as crea una atmósfera de trabajo muy fluida, en la que desde el primer día de taller ya se genera un entendimiento implícito, lo cual hace que se avance más rápido en el trabajo, a lo que se añade la alta motivación de participantes y profesorado».
La directora de la Escuela de Teatro destaca también «el alto nivel de satisfacción» de alumnado y profesorado, una valoración positiva que se refleja tanto en las encuestas internas como en los comentarios informales de los participantes.
También se ha referido a uno de los objetivos de esta edición, que era consolidar la colaboración iniciada en 2025 entre la Escuela de Teatro de la UNIA y el Festival Internacional de Teatro Clásico de Almagro (FITCA). Una colaboración que se plantea para «favorecer el encuentro y enriquecimiento mutuo entre profesionales de la escena, estudiantes y aficionados de artes escénicas, y la ciudadanía en general, tratando de acercar, de alguna manera, Baeza a Almagro, y Almagro a Baeza, con todas sus resonancias escénicas, artísticas, históricas, y culturales», subraya.
«Bajo ese marco, agrega, se ha celebrado, con organización del Festival de Almagro y patrocinio de la UNIA, una actividad que queda para el histórico de la Escuela de Teatro y de la propia UNIA: el taller Directing the Actor (Dirigir al actor), impartido por Declan Donnellan y Nick Ormerod, fundadores y directores artísticos de la compañía Cheek-by-Jowl, realizado del 13 al 15 de julio en el Parador de Almagro e incluido en la programación del Festival Internacional de Teatro Clásico de Almagro en su 49ª edición».
Esta vigesimosegunda edición se ha realizado del 6 al 10 de julio con cuatro talleres; Juego, comicidad y creación, impartido por Antón Valén, actor, clown y pedagogo teatral, y Drama in education (DIE). La imaginación como herramienta en el trabajo con comunidades, que imparte Lucía Miranda, dramaturga, directora de escena y arteducadora; Del movimiento a la palabra escénica - El cuerpo como motor de la palabra, a cargo de Lidia Otón, actriz y pedagoga actoral, y Taller de escritura teatral: ¿Cuáles son las verdaderas normas? (De la forma dramática a la forma abierta), impartido por Victoria Spunzberg, dramaturga, directora y profesora de Dramaturgia.
Y se ha completado con la master class ofrecida por la actriz y pedagoga actoral, Lidia Otón, y la conferencia Teatro independiente en España, a cargo de César Oliva Olivares, fundador de la Escuela de Teatro de la UNIA.
La principal novedad de la edición este año sido la inclusión de la actividad transversal Espacio Abierto, que «ha consistido en habilitar una franja de tiempo, de entre una y dos horas, en cada uno de los talleres, durante la cual se impartía una clase abierta a la que podían asistir los participantes del resto de talleres. De este modo, se ha cubierto una inquietud del alumnado de la Escuela de Teatro: conocer por dentro, de alguna manera, qué está sucediendo y cuál es la metodología en todos los talleres, además de en aquel o aquellos en los cuales están matriculados/as», explica la directora de la Escuela de Teatro.
Por tanto y, a modo de balance, manifiesta que «esta edición nos resulta muy satisfactoria, pues recoge la tradición, la continua innovación y la colaboración con el Festival de Almagro, sumando la energía especial y la entrega que traen, verano tras verano, profesorado y participantes. Se trata pues de una Escuela de Teatro viva, una actividad formativa que diseñamos en cada edición en contacto con su entorno, la experiencia anterior y la retroalimentación de alumnado y profesorado, por todo lo cual consideramos que, año tras año, la Escuela de Teatro de la UNIA se consolida como un proyecto hermoso, de valía artística y pedagógica, y por ende, cultural y social».
UNIAescenaBaeza
Por último, se ha referido a UNIAescenaBaeza y los dos espectáculos ofrecidos en el Teatro Montemar: El arte de ser comediante, de la compañía Teatro a Bocajarro (Madrid), con autoría y dirección de Laura Garmo y Nacho León; y Paüra, de la compañía Lucas Escobedo (Alicante-Madrid), bajo la dirección del propio Lucas Escobedo, contando en la dirección y composición musical con Raquel Molano.
«Los dos espectáculos presentados han sido un éxito, con alta asistencia de público y lleno casi absoluto en el segundo día de la muestra. Ese día la representación se dedicó a la memoria de la actriz, dramaturga y productora Rocío Bernal, recientemente fallecida, y cuyo espectáculo Cría cuerdos con la compañía Deconné estaba inicialmente programado en UNIAescena», concluye Nieves Pérez Abad.
,La fundación de la Real Academia de San Carlos de México a finales del siglo XVIII supuso una transformación radical en el panorama cultural iberoamericano, al convertirse en el epicentro visual del continente y alterar de forma definitiva la consideración social y laboral de los creadores.
Así lo ha manifestado Andrés Úbeda de los Cobos, jefe de Colección de Pintura Española del Siglo XVIII y Goya del Museo del Prado, en el marco del curso de verano de la Universidad Internacional de Andalucía (UNIA) Las Academias de las Bellas Artes. El modelo de San Carlos de México. Una propuesta, organizada en la Sede de La Rábida en colaboración con la Universidad Nacional Autónoma de México (UNAM) y con el apoyo de la Diputación de Huelva, donde ha intervenido para repasar el legado de este centro pionero fundado hace casi 250 años.
Para el especialista, la creación de esta institución representó un salto cuantitativo y cualitativo para la profesión. «Supuso un paso adelante extraordinariamente importante. Representó el paso del taller personal de cada artista a una institución amparada por el Estado, lo que les otorgó posibilidades de formación y desarrollo profesional que antes no tenían», ha aseverado Úbeda de los Cobos.
La academia logró centralizar los esfuerzos no solo de la capital mexicana, sino de todo el Virreinato de la Nueva España, exportando la metodología de San Fernando de Madrid e integrando el dibujo como un elemento clave para articular la masa laboral y las artesanías de la época.
Respecto al debate sobre si la academia fue un instrumento de dominación política o un foco de síntesis cultural, el ponente ha recalcado que ambos procesos convivieron de forma paralela. «Se convirtió en las dos cosas al mismo tiempo, porque no son conceptos estrictamente antagónicos», ha explicado. En este sentido, ha precisado que si bien se buscó imponer una estética centralizada, «simultáneamente ofreció a los artistas locales todas las posibilidades de promoción y desarrollo personal que no existían previamente».
Fruto de esa interacción, la institución evitó ser una copia servil de la metrópoli. «El legado que hoy atesora es el producto perfectamente integrado de aquello que llega desde la metrópoli y aquello que la propia Ciudad de México fue capaz de crear. No se trata de una institución estrictamente subsidiaria de lo que se ordenaba desde Madrid, ya que contó con una identidad propia», ha remarcado.
Asimismo, el experto ha abordado cómo la rigidez normativa inicial de la academia fue cediendo terreno con el paso del tiempo ante el empuje de la libertad creativa. «Aunque la academia nació con la voluntad de unificar la producción artística, al final se reveló la necesidad de dar juego a la personalidad individual de cada uno de los artistas que la integraban», ha argumentado.
Por último, al evaluar las lecciones que este modelo histórico ofrece a las disciplinas contemporáneas, Úbeda de los Cobos ha situado el foco en la capacidad de innovación. «Lo que destacaría sobre todo es el elemento fundamentalmente creativo: la voluntad de ser capaces de crear algo nuevo a partir del conocimiento y de la existencia de una producción artística previa», ha concluido.
Cursos de verano
Andrés Úbeda de los Cobos es ponente del curso de verano Las academias de las Bellas Artes. El modelo de San Carlos de México, organizado por la Universidad Internacional de Andalucía del 21 al 23 de julio en su Sede de La Rábida.
Este encuentro, en colaboración con la Universidad Nacional Autónoma de México (UNAM) y con el apoyo de la Diputación de Huelva, a través de la Cátedra de Inteligencia Institucional, analiza la circulación de técnicas, iconografías y valores estéticos en Iberoamérica, desde los talleres gremiales hasta la implantación de las academias de bellas artes a finales del siglo XVIII.
Más información:
https://www.unia.es/estudios-y-acceso/oferta-academica/cursos-de-verano/las-academias-de-bellas-artes-el-modelo-de-san-carlos-de-mexico
,El acceso a herramientas de inteligencia artificial no basta para rentabilizar los ahorros de los ciudadanos si no se cuenta con una base formativa sólida. Así, la tecnología solo es eficaz cuando se sabe qué preguntarle y dónde están las ventajas que se quieren potenciar. Así lo ha expuesto José Luis García López en el curso de verano 10 talleres de inteligencia artificial: herramientas gratuitas del ecosistema de Google aplicadas a la educación, la empresa y las finanzas. Una propuesta de la Universidad Internacional de Andalucía, organizada de manera virtual desde su Sede de La Rábida.
Esta falta de cualificación y aprendizaje mínimo previo opera, según el analista, como el principal factor de riesgo cuando los usuarios deciden delegar sus finanzas personales en los nuevos asistentes virtuales. El ponente ha desmitificado la concepción de la IA como un salvavidas financiero automático. «La inteligencia artificial es un paso de optimización para cuando ya se tiene un nivel de conocimiento», ha aclarado.
A través del uso de prompts especializados, estas herramientas permiten elevar de forma proporcional la probabilidad de éxito de cualquier sistema de inversión, actuando siempre como un complemento y nunca como un sustituto del criterio humano. «La IA es un apoyo para mejorar el rendimiento de algo que ya se posee, pero no puede suplantar la falta de conocimiento. Hay que saber qué preguntarle y dónde están las ventajas que se quieren potenciar», ha señalado este experto de Trading Global Group MGJ.
Cuestionado sobre dónde debe poner el usuario la línea roja antes de mostrar datos bancarios a una inteligencia artificial, García López ha señalado que para blindar su seguridad, el procedimiento idóneo consiste en realizar simulaciones iniciales mediante «cuentas demo» que replican exactamente los costes y las garantías de los mercados pero operan bajo entornos y datos ficticios. De este modo, cuando el asistente virtual procesa la estrategia de inversión definitiva, la fórmula resultante se implanta en la cuenta real por parte del inversor, sin necesidad de intervención de la IA.
Para el especialista, las cifras de participación en los mercados financieros dentro del ámbito nacional constatan una brecha notable respecto a otros países desarrollados. «En España el inversor doméstico carece de interés y cualificación en comparación con países como Estados Unidos, donde al 30% de la población le importa la inversión», ha aseverado García López, detallando que en el territorio español la comunidad dedicada a estas operaciones es residual. «En España hay unas 60.000 personas que se dedican al trading, una cuota de mercado absolutamente insignificante», ha precisado.
Cursos de Verano
José Luis García López es ponente en el curso de verano 10 talleres de inteligencia artificial: herramientas gratuitas del ecosistema de Google aplicadas a la educación, la empresa y las finanzas, organizado del 20 al 23 de julio por la Universidad Internacional de Andalucía a través de su Sede de La Rábida.
Se trata de la tercera edición de este curso, que se amplía y actualiza con talleres sobre la nueva generación de herramientas de IA (IA multimodal, asistentes inteligentes, automatización, agentes y entornos de productividad avanzada). Se trata de una propuesta de alta oportunidad por el creciente impacto de la IA en educación superior, empresa y mercados financieros, y la demanda de formación práctica con transferencia inmediata.
Más información: https://www.unia.es/estudios-y-acceso/oferta-academica/cursos-de-verano/10-talleres-de-inteligencia-artificial-herramientas-gratuitas-del-ecosistema-de-google-aplicadas-a-la-educacion-la-empresa-y-las-finanzas
,La Universidad Internacional de Andalucía (UNIA) ha comenzado el curso Arqueología del cuaternario: teorías, métodos y prácticas, organizado por la Sede Antonio Machado de Baeza (Jaén) y por el Centro de Investigaciones Prehistóricas de Sierra Mágina (Paleomágina), y dirigido por Marco Antonio Bernal y José María Hidalgo, de Paleomágina, y Mª del Carmen Jorge García, de la Universidad Carlos III de Madrid.
El curso celebra su octava edición y un año más tratará de aportar al alumnado una formación integral y de excelencia en el ámbito de la Arqueología del Cuaternario y la Evolución Humana. Se imparte del 17 de julio al 2 de agosto de 2026, en Bedmar (Jaén).
Sus principales objetivos son proporcionar una formación práctica y teórica, a los 24 alumnos matriculados, en la metodología y técnicas arqueológicas del Cuaternario y realizar una investigación y puesta en valor de una parte de la riqueza arqueológica patrimonial de Bedmar, como es el yacimiento de la Cueva del Nacimiento del río Cuadros.
La directora del Museo Nacional y Centro de Investigación de Altamira, Pilar Fatás, ha impartido la conferencia inaugural, que ha tratado sobre Las mujeres de Altamira – evidencias, relatos y construcción del imaginario.

El director de la Sede Antonio Machado, José Manuel Castro, ha felicitado a los directores del curso, Marco Antonio Bernal, Mª del Carmen Jorge y José María Hidalgo, «por la magnífica propuesta que de nuevo ha cubierto todas las plazas disponibles, mi agradecimiento al profesorado, más de 30 especialistas procedentes de diversos centros universitarios y de investigación de toda España, y por supuesto al alumnado, que es la razón de ser de este curso, por su decisión de dedicar esta segunda quincena de julio a la formación en Arqueología, de la mano de la Internacional de Andalucía y del Centro Paleomágina».
Como en anteriores ediciones, el curso tiene una parte práctica y otra teórica. Así, el horario matinal se dedica a las excavaciones arqueológicas y el trabajo de laboratorio y el de tarde, a conferencias y prácticas con investigadores especialistas en la materia.
Para ello, el curso cuenta con una treintena de docentes, entre ellos, Javier Baena, Patricia Ríos, Concepción Torres y Nuria Castañeda, de la Universidad Autónoma de Madrid (UAM); Francisco Javier Fernández de la Peña, de Dibujantes de Arqueología; Leonor Peña, Antonio Delgado y Mónica Ruiz , del Consejo Superior de Investigaciones Científicas; Mª Soledad Maíz, de Fíbula. Didáctica del Patrimonio; Rafael Bermúdez, del Grupo Espeleológico G-40 de Priego de Córdoba; Félix Ríos, de la Sociedad Gaditana de Historia Natural; José Ramos Muñoz y Manuel Jesús Parodi, de la Universidad de Cádiz (UCA); José Antonio Riquelme, José Luis Sanchidrián y Mª Ángeles Medina, de la Universidad de Córdoba (UCO); Pablo Garrido, de la Consejería de Cultura y Patrimonio Histórico de la Junta de Andalucía; José Yravedra y Verónica Estaca, de la Universidad Complutense de Madrid (UCM); Sebastián Pérez, de la Universidad de Cantabria (UC) o José Juan Redondo, Francisco José Bermúdez, Jesús Torres y Antonio López , investigadores de Paleomágina.
,La Universidad Internacional de Andalucía (UNIA) ha inaugurado hoy en su Sede de La Rábida el curso de verano Las academias de Bellas Artes. El modelo de San Carlos de México. Una propuesta que abordará hasta el 23 de julio la circulación de técnicas, iconografías y valores estéticos en Iberoamérica, desde los talleres gremiales hasta la implantación de las academias de bellas artes a finales del siglo XVIII.
Dirigido por el catedrático Rafael López Guzmán, de la Universidad de Granada, y la profesora Angélica Velázquez Guadarrama, de la UNAM, este curso conecta historia del arte, antropología y teoría pedagógica, concediendo un papel central a la Academia de San Carlos de México. Fundada por Carlos III, es la única institución de este tipo consolidada en el periodo virreinal y sirvió de modelo para las academias creadas posteriormente en otros países americanos a lo largo del siglo XIX.
El acto de apertura ha contado con la participación del rector de la UNIA, José Ignacio García, acompañado por el director de la Universidad Nacional Autónoma de México (UNAM) en España, Ciro Murayama, y el coordinador de Cooperación Internacional de la Diputación de Huelva, José Leñero, institución colaboradora a través de la Cátedra de Inteligencia Institucional.
El rector de la UNIA ha puesto en valor como este curso “abre una ventana a nuestro pasado común, el de Andalucía y México, a través del arte. Desde las influencias, el aprendizaje de ida y vuelta, configurando un ecosistema donde la Academia de San Carlos fue pionera y modelo para toda Iberoamérica”. En ese sentido, ha agradecido la implicación de la UNAM, “que tiene desde hace un siglo la responsabilidad de perpetuar el legado histórico de esta academia”, y el apoyo de la Diputación de Huelva, “para que la esencia iberoamericana perdure a través de propuesta como esta 83 años después de los primeros cursos”.
El director de la UNAM en España ha subrayado cómo este curso fortalece las relaciones entre España y México, desde el conocimiento y las relaciones entre personas. “Para nosotros es importante que aprovechemos la oportunidad de estrechar vínculos, con el español como lengua de ciencia y de cultura, desde nuestros valores compartidos”, ha señalado Murayama, quien ha adelantado una nueva edición, para el próximo verano, con el foco puesto en los cincuenta años de relaciones diplomáticas hispano mexicanas.
El coordinador de Cooperación Internacional de la Diputación de Huelva ha reivindicado La Rábida como lugar de encuentro, de trabajo y como punto de interés para el desarrollo de conocimiento. “Desde Diputación optamos por este curso por cómo fomenta los valores iberoamericanos, desde el arte y desde el humanismo, con una visión plural” y, viendo el resultado de programa y matrícula, “ha sido un acierto”, ha señalado.
El encuentro Las academias de Bellas Artes. El modelo de San Carlos de México contará durante tres días con un importante elenco de especialistas procedentes de instituciones de España y México. Entre ellos, Andrés Úbeda de los Cobos, del Museo Nacional del Prado, y las profesoras Lola Caparrós Masegosa y Yolanda Guasch Marí, de la Universidad de Granada, abordarán la proyección española de este modelo formativo. Por parte mexicana, participan María José Esparza Liberal y Hugo Antonio Arciniega Ávila, ambos de la UNAM, que profundizarán en el funcionamiento y la evolución de la Academia de San Carlos.
Más información:
https://www.unia.es/estudios-y-acceso/oferta-academica/cursos-de-verano/las-academias-de-bellas-artes-el-modelo-de-san-carlos-de-mexico
,Máster Universitario en Profesorado (MAES)
Especialidad: Lengua Extranjera – Portugués
Preinscripción
Una alternativa que quizá todavía no habías considerado.
La especialidad de Lengua Extranjera Portugués del MAES abre una vía menos saturada para el acceso a la docencia. Si tienes formación en Filología, Traducción e Interpretación, Lenguas Modernas, Lingüística u otras titulaciones relacionadas con los idiomas, podrías cumplir los requisitos de acceso.
Además, elegir esta especialidad para cursar el MAES no significa que en el futuro tengas que presentarte necesariamente a las oposiciones de Portugués. Podrás optar a otras especialidades siempre que cumplas los requisitos establecidos en la convocatoria.
Menos competencia
Una de las especialidades con menor ratio de opositores por plaza en Andalucía.
Puente ibérico
La lengua portuguesa gana peso en el currículum escolar y en programas bilingües.
Flexibilidad futura
Cursar Portugués no te ata: podrás presentarte a otras especialidades si cumples requisitos.
¿Cumples los requisitos?
Titulaciones habilitantes para acceder al MAES en la especialidad de Lengua Extranjera – Portugués.
- Grado o Licenciatura en Filología (Portuguesa, Románica, Hispánica u otras)
- Grado en Traducción e Interpretación (con Portugués en el itinerario)
- Grado en Lenguas Modernas o Estudios de Asia y África
- Grado en Lingüística o Estudios Literarios
- Otras titulaciones acompañadas de acreditación B2/C1 de Portugués
60 ECTS estructurados para tu formación docente.
Módulo Genérico
Aprendizaje, procesos educativos, sociedad y familia.
Específico – Portugués
Didáctica de la lengua portuguesa e innovación docente.
Prácticum
Estancia en centros educativos con tutor asignado.
TFM
Trabajo Fin de Máster orientado a la práctica docente.
Da el paso. Enseña Portugués.
Preinscripción abierta del 8 al 15 de septiembre de 2026 para el curso 2026-2027. Plazas limitadas.
-
Iniciar preinscripción (activa a partir del 8 de septiembre)
-
Descargar folleto

