En la actualidad, la velocidad de la generación de datos es constante y está en continuo crecimiento, lo que permite potenciar el aprendizaje de la Inteligencia Artificial y ayudar a empresas y profesionales a tomar decisiones más informadas.
En este artículo te explicamos qué es el Machine Learning y cómo puede ayudarte a potenciar tu futuro profesional.
Qué es el Machine Learning y para qué sirve
El Machine Learning es una rama específica dentro de la inteligencia artificial (IA) que se especializa en la resolución de problemas específicos a través del aprendizaje autónomo y el análisis de grandes cantidades de datos.
Este aprendizaje automático es posible debido al desarrollo y entrenamiento de algoritmos y modelos predictivos que permiten identificar patrones y realizar predicciones en base al análisis de datos masivos, por lo que a mayor volumen de datos obtenga, mayor será su desempeño.
¿Cómo funciona el aprendizaje automático?
El aprendizaje automático es el proceso de optimizar el modelo predictivo en base a un entrenamiento con muestras de datos, de forma que la máquina identifica y aprende las relaciones matemáticas entre los patrones encontrados en las muestras, permitiéndole realizar predicciones precisas sobre nuevos datos.
Este sistema permite a la máquina mejorar su rendimiento a medida que obtenga más datos, permitiéndole desarrollar tareas y tomar decisiones sin necesidad de ser programada con instrucciones específicas para cada tarea o caso concreto.
Para qué sirve el Machine Learning y ejemplos
El Machine Learning puede utilizarse para múltiples tareas, pero podemos destacar las siguientes funciones:
- Predecir resultados: permite estimar valores o comportamientos futuros a partir de datos previos.
Por ejemplo: una entidad bancaria lo puede emplear para predecir la probabilidad de impago de un cliente en función de variables como sus ingresos, nivel de endeudamiento o historial crediticio para evaluar el riesgo antes de la concesión de un préstamo.
- Clasificar información: puede utilizarse para reconocer patrones en los datos y asignarlos a una categoría concreta en función de sus características.
Por ejemplo: permite detectar si un correo es spam en función de las características y similitudes a mensajes ya etiquetados como spam, como patrones del texto o palabras utilizadas.
- Personalizar experiencias: permite predecir las preferencias de los usuarios y sugerir contenido relevante adaptado a sus intereses.
Por ejemplo: Youtube utiliza un modelo de aprendizaje automático para analizar los intereses y hábitos de consumo de sus usuarios en la plataforma para recomendarles videos acorde a sus preferencias.
- Detectar anomalías: permite detectar patrones que se desvían de los habitual dentro de un conjunto de datos.
Por ejemplo: en ciberseguridad la detección de datos anómalos puede indicar que pueden existir amenazas en la seguridad, fallos de infraestructura o actividad inusual en la red, lo que permite actuar rápidamente frente a incidentes críticos.
Machine learning vs Deep Learning
El Deep Learning es una rama dentro del Machine Learning, la diferencia sustancial es que el primero utiliza redes neuronales, inspiradas en las neuronas biológicas del cerebro humano, para extraer los patrones y características de los datos, mientras que otros modelos de aprendizaje automático suelen apoyarse en modelos estadísticos más tradicionales como regresiones estadísticas, análisis de hipótesis y árboles de decisión.
Estas redes neuronales se distinguen principalmente de otros algoritmos tradicionales por su estructuración en capas, lo que les permite procesar la información paso a paso y analizar patrones más complejos, resultando muy útil en el análisis de imágenes o reconocimiento de voz.
La relación entre el Machine Learning y el Big Data
El Big data es la generación de datos masivos, es decir, un gran volumen de datos de gran variedad y que se generan a gran velocidad, por otro lado, el Machine Learning se basa en el aprendizaje automático en base al análisis de datos, por lo que es posible procesar y limpiar grandes volúmenes de datos, almacenarlos y entrenar a los algoritmos de aprendizaje automático para obtener resultados más precisos y valiosos.
Tipos de Machine Learning
Dependiendo de la tarea que queramos realizar con el algoritmo y los datos disponibles, podemos identificar cinco distintos tipos de aprendizaje o algoritmos de machine learning:
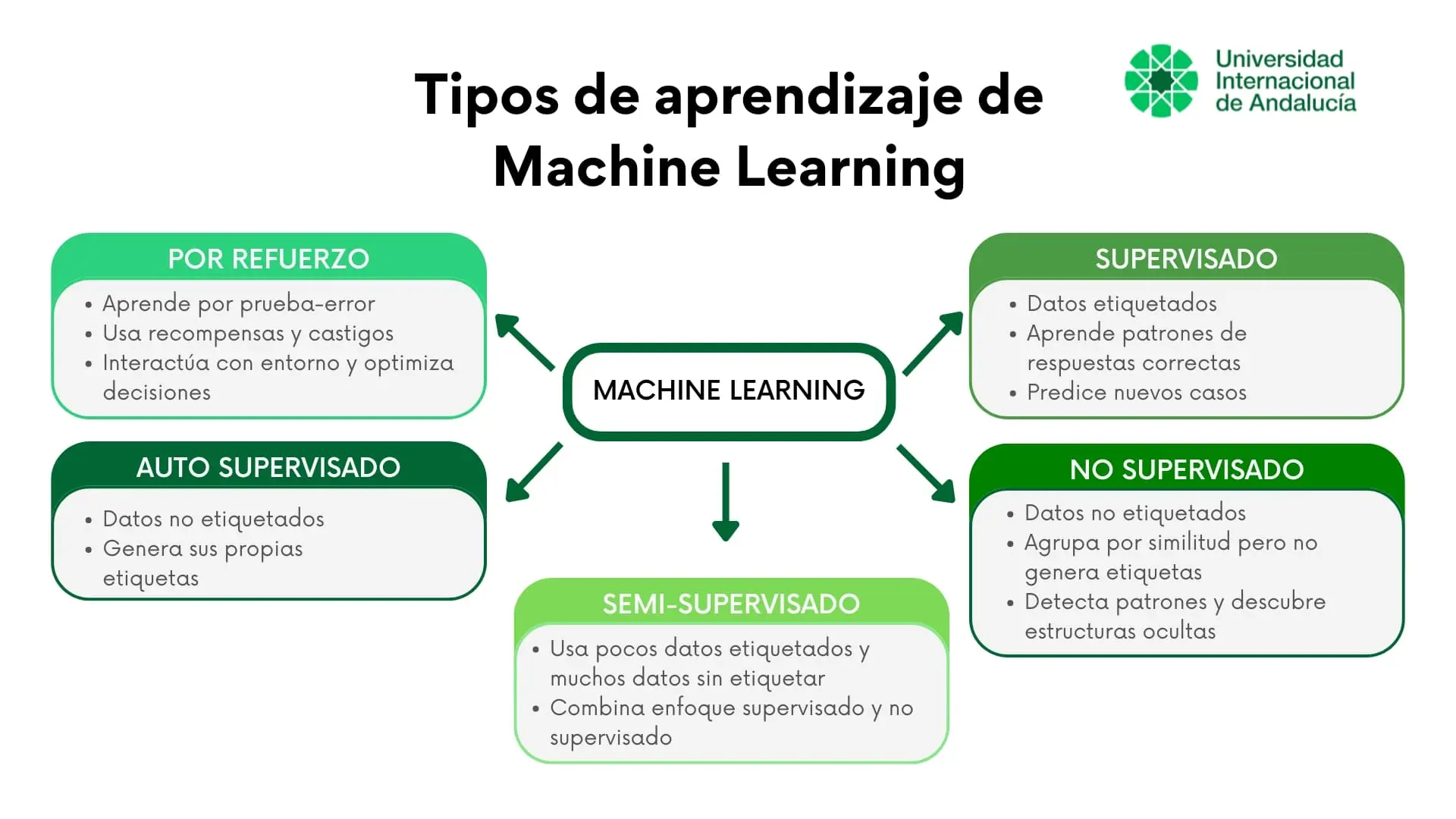
Aprendizaje supervisado
Los modelos de aprendizaje supervisado se entrenan con datos etiquetados, es decir, con ejemplos en los que ya se conoce el resultado final. En cada caso, el sistema recibe una serie de datos sobre la situación analizada, lo que en términos técnicos se conoce como variables de entrada, y también el resultado correspondiente, o variable de salida. A partir de esos ejemplos, el algoritmo aprende la relación entre ambos y puede utilizarla después para predecir qué ocurrirá en nuevos casos.
Por ejemplo, volviendo al ejemplo de la entidad bancaria, puede entrenar un modelo de aprendizaje supervisado con los datos de sus clientes como su capacidad de ahorro, historial crediticio o nivel de endeudamiento. En cada caso, además, se indica el resultado final, es decir, si hubo impago o no, lo que se conoce como etiquetar los datos. A partir de esa información, el sistema aprende a reconocer patrones que le permiten estimar si los nuevos clientes devolverán el préstamo a tiempo.
Aprendizaje no supervisado
Los modelos de aprendizaje no supervisado, a diferencia del anterior, no necesitan de la intervención humana para etiquetar previamente los datos, ya que utiliza algoritmos de autoaprendizaje que estructuran la información en función de sus similitudes, patrones y diferencias a través de un análisis cluster o por conglomerados.
Debido a ello, es un sistema de aprendizaje muy útil para identificar nuevos patrones en los datos que no han sido previamente identificados o para conjuntos de datos muy grandes y complejos.
Por ejemplo: si la entidad bancaria utilizase un modelo de aprendizaje no supervisado, el sistema no predeciría directamente si un cliente incurrirá en impago, ya que no se le indica ese resultado durante el entrenamiento. Su función es agrupar automáticamente a los clientes según características similares, como su edad, nivel de ingresos, historial crediticio, etc. A partir de esa segmentación, la entidad podría identificar perfiles con rasgos comunes y detectar grupos que, tras un análisis posterior, presenten una mayor o menor probabilidad de impago.
En resumen, la diferencia sustancial es que el no supervisado descubre patrones y el supervisado predice resultados.
Aprendizaje semi-supervisado
El aprendizaje semi-supervisado se trata de una combinación entre el modelo de aprendizaje supervisado y el no supervisado.
Para entrenar el modelo, se utiliza una pequeña cantidad de datos etiquetados y una cantidad mucho mayor de datos no etiquetados. Así, se reduce la intervención humana, ya que no es necesario clasificar manualmente todos los ejemplos. Los datos etiquetados permiten al sistema aprender la relación entre la información disponible y el resultado esperado, mientras que los datos no etiquetados le ayudan a detectar estructuras y patrones que mejoran el aprendizaje.
Aprendizaje autosupervisado (SSL)
El aprendizaje autosupervisado (SSL) permite entrenar un modelo con datos no etiquetados, pero a diferencia del aprendizaje no supervisado, el propio sistema genera sus etiquetas a partir de la estructura de los datos.
Para ello, se le plantea una tarea intermedia, como predecir una palabra que falta en un texto o reconstruir una parte oculta de una imagen. De este modo, aunque nadie le indique directamente cuál es la respuesta final de una tarea concreta, el modelo aprende patrones y relaciones útiles dentro de la información, permitiéndole realizar posteriormente tareas más complejas, como clasificar textos, responder preguntas o reconocer imágenes.
En la práctica, este enfoque se utiliza principalmente en modelos de deep learning, ya que suelen ser los más adecuados para trabajar con grandes volúmenes de datos y extraer patrones complejos de forma automática gracias a sus redes neuronales.
Por ejemplo: este modelo de aprendizaje es muy utilizado en los escáneres médicos, ya que es posible entrenar al sistema con multitud de resonancias sin etiquetar permitiendo aprender características anatómica que permita posteriormente detectar posibles tumores.
Aprendizaje por refuerzo (RL)
El aprendizaje por refuerzo (RL) es un tipo de aprendizaje automático en el que el sistema aprende mediante prueba y error. A diferencia del aprendizaje supervisado, no recibe de antemano la respuesta correcta, sino que interactúa con un entorno y va tomando decisiones para alcanzar el mejor resultado posible.
Cuando una acción produce un resultado favorable, el sistema recibe una recompensa; si el resultado es negativo, recibe una penalización. A partir de esa experiencia, aprende progresivamente qué decisiones le permiten obtener mejores resultados.
Por ejemplo: aplicando el aprendizaje por refuerzo al sector de la domótica, un robot aspirador puede aprender a moverse por una vivienda mediante prueba y error. Cuando toma decisiones que le permiten limpiar mejor y evitar obstáculos, recibe una recompensa; si se equivoca, recibe una penalización. Con el tiempo, aprende qué acciones le ayudan a limpiar de forma más eficiente y obtener mejores resultados.
Algoritmos de Machine Learning
Para entrenar modelos, el machine learning utiliza distintos algoritmos, es decir, conjuntos de reglas y procedimientos matemáticos que le permiten aprender patrones a partir de los datos.
La elección de unos u otros depende del tipo de aprendizaje automático, del problema que se quiera resolver y de la información disponible para entrenar el sistema. Por ello, a continuación resumimos los algoritmos más utilizados en función de cada tipo de aprendizaje automático
Principales algoritmos de aprendizaje supervisado
Algunos de los algoritmos de aprendizaje supervisado más utilizados son:
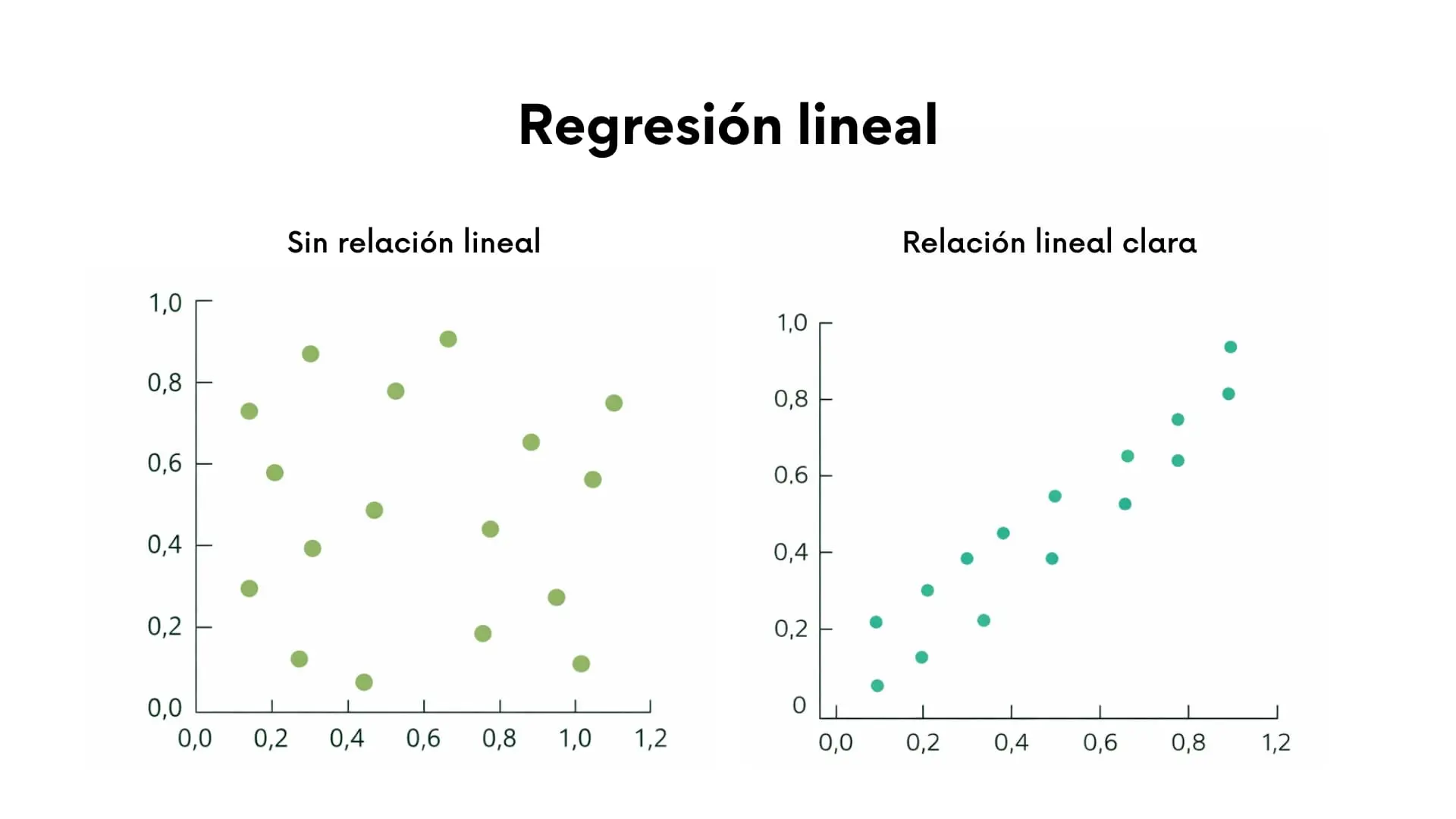
1. Regresión lineal
Es una técnica estadística que permite generar un modelo lineal que describa la relación entre una variable dependiente (x) y uno o más variables independientes (y), dependiendo si el modelo es una regresión lineal simple (una sola variable independiente) o una regresión lineal múltiple (dos o más variables independientes).
Este modelo busca encontrar la recta que mejor se ajusta a los datos para explicar cómo cambia la variable dependiente en función de la variable o variables independientes.
De forma visual, esta relación puede representarse mediante un diagrama de dispersión. Cuanto más cerca se sitúan los puntos de una línea recta, más clara es la relación lineal entre las variables.
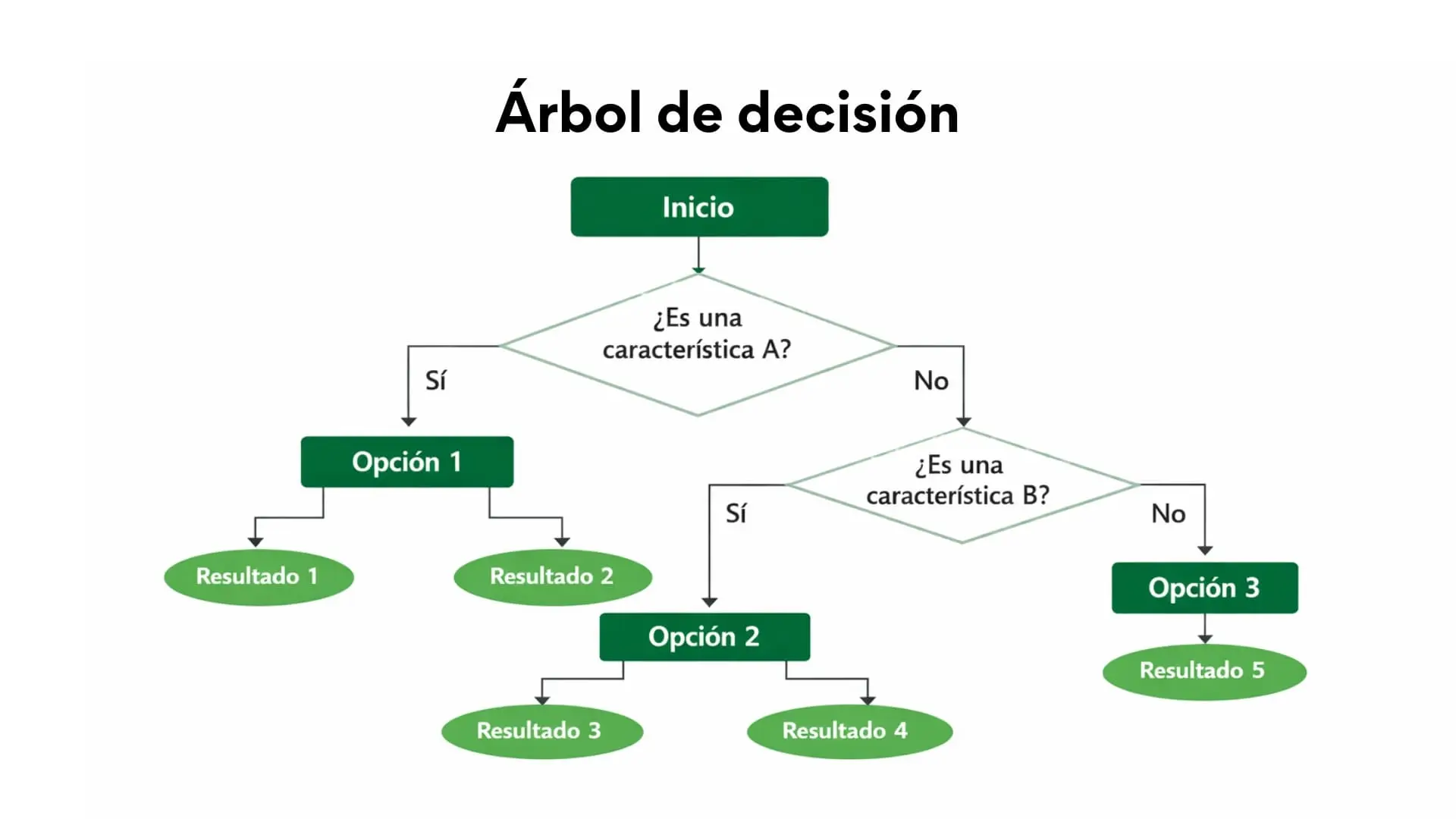
2. Árbol de decisión
Un árbol de decisión es un modelo estadístico que toma decisiones a partir de preguntas sucesivas sobre los datos, utilizando una estructura jerárquica similar a un árbol.
Su objetivo es dividir los datos en grupos cada vez más homogéneos, dividiendo en cada paso la información en función de la variable o característica que mejor diferencia a los datos según el resultado que se quiera predecir, obteniendo una clasificación final.
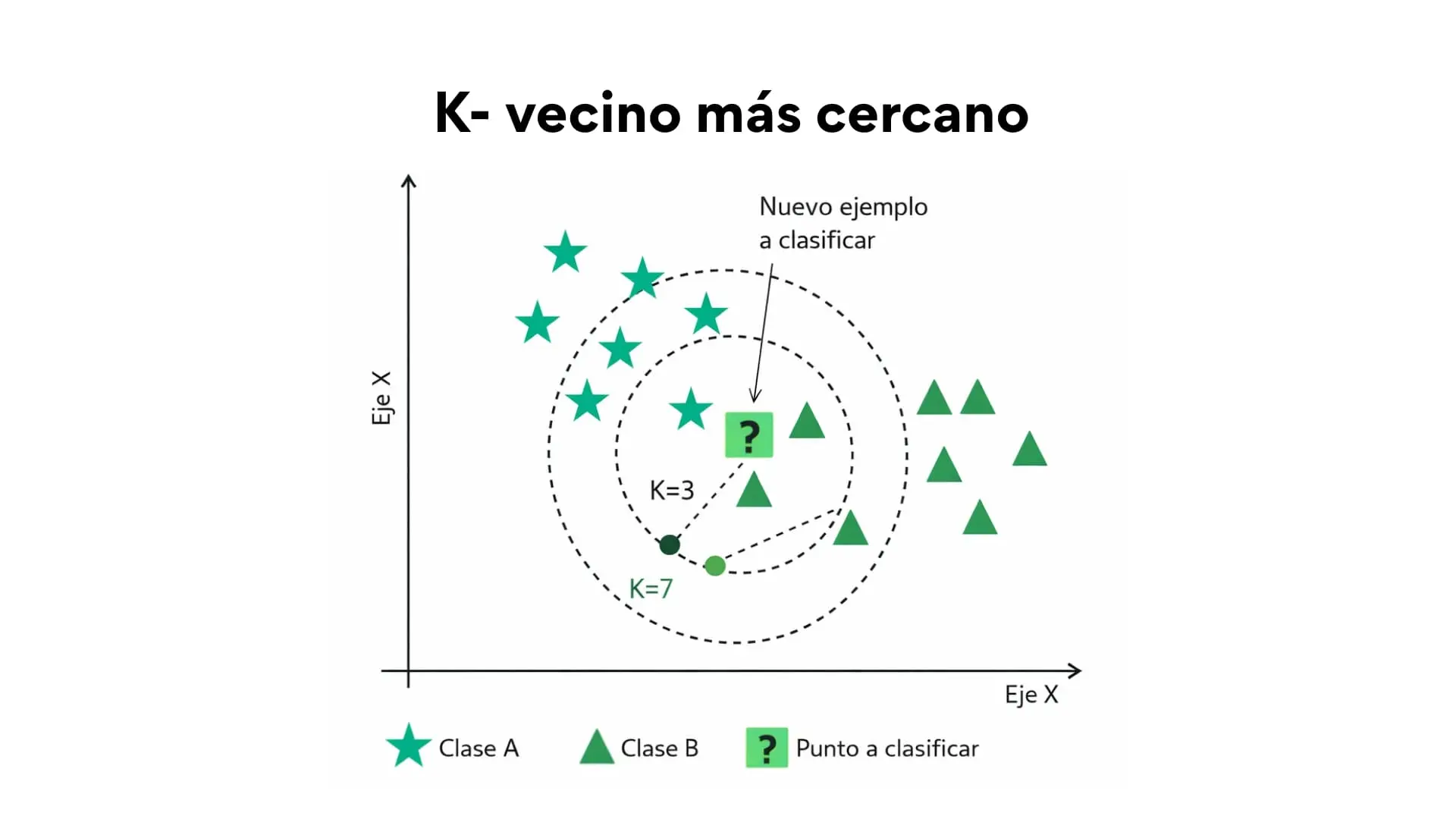
K- vecino más cercano
El método del K-vecino más cercano es un técnica estadística que clasifica un nuevo caso en función de los ejemplos más parecidos que ya conoce, comparando las características del nuevo dato con las de otros datos ya clasificados.
Esa comparación se hace midiendo la distancia entre unos datos y otros, de forma que cuanto menor es la distancia, mayor es la similitud. Su rendimiento dependerá de cómo se mida esa distancia, del número de vecinos seleccionados y de la calidad de las variables utilizadas.
Principales algoritmos de aprendizaje no supervisado
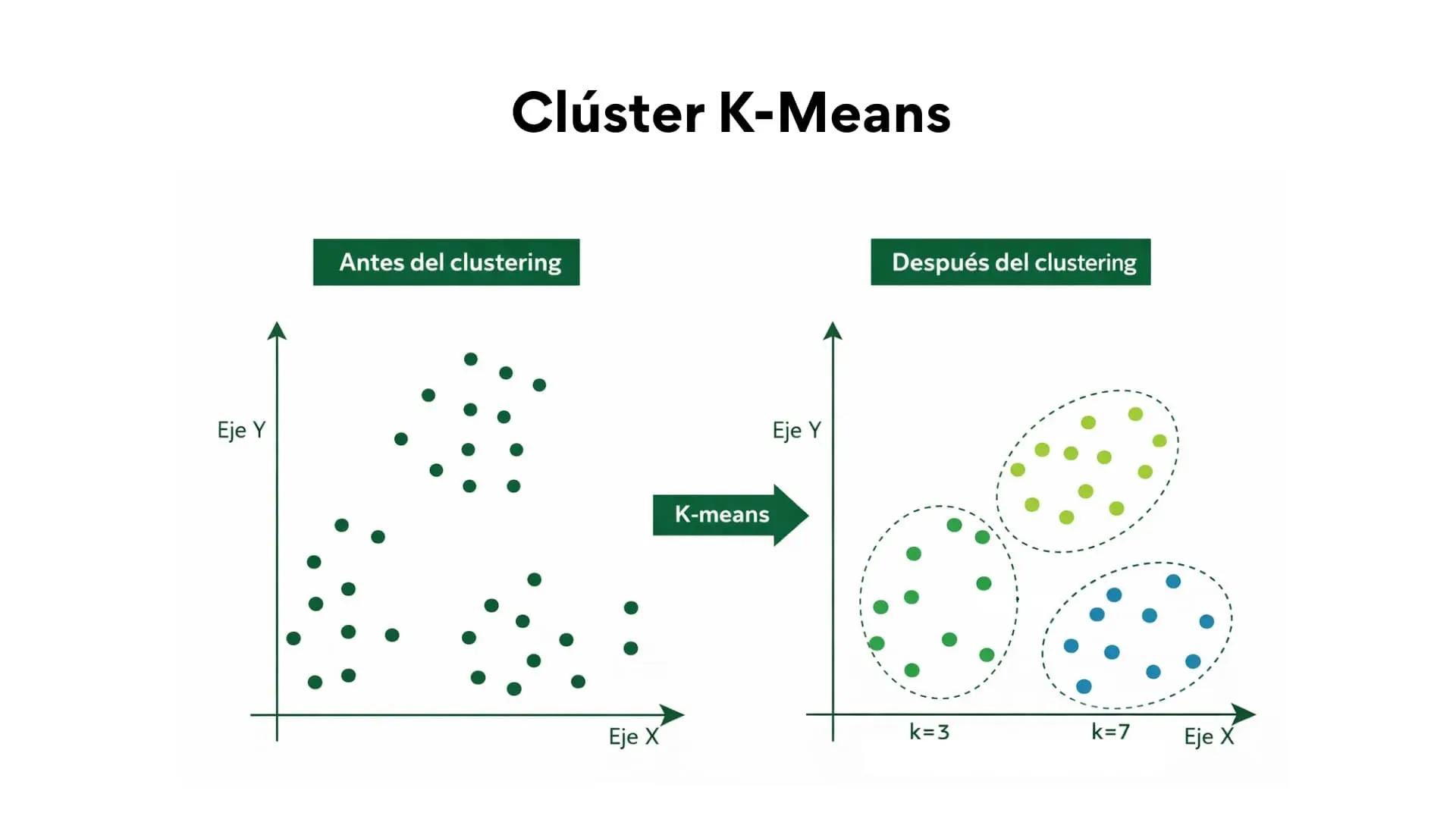
Cluster de K-means
El clustering de k-medias es un algoritmo que divide en un número predeterminado de grupos o clústeres, seleccionando un número de grupos y asignando a cada observación al grupo cuyo centro esté más próximo y recalculando de forma iterativa la media de cada grupo para obtener los conjuntos de datos más homogéneos posibles.
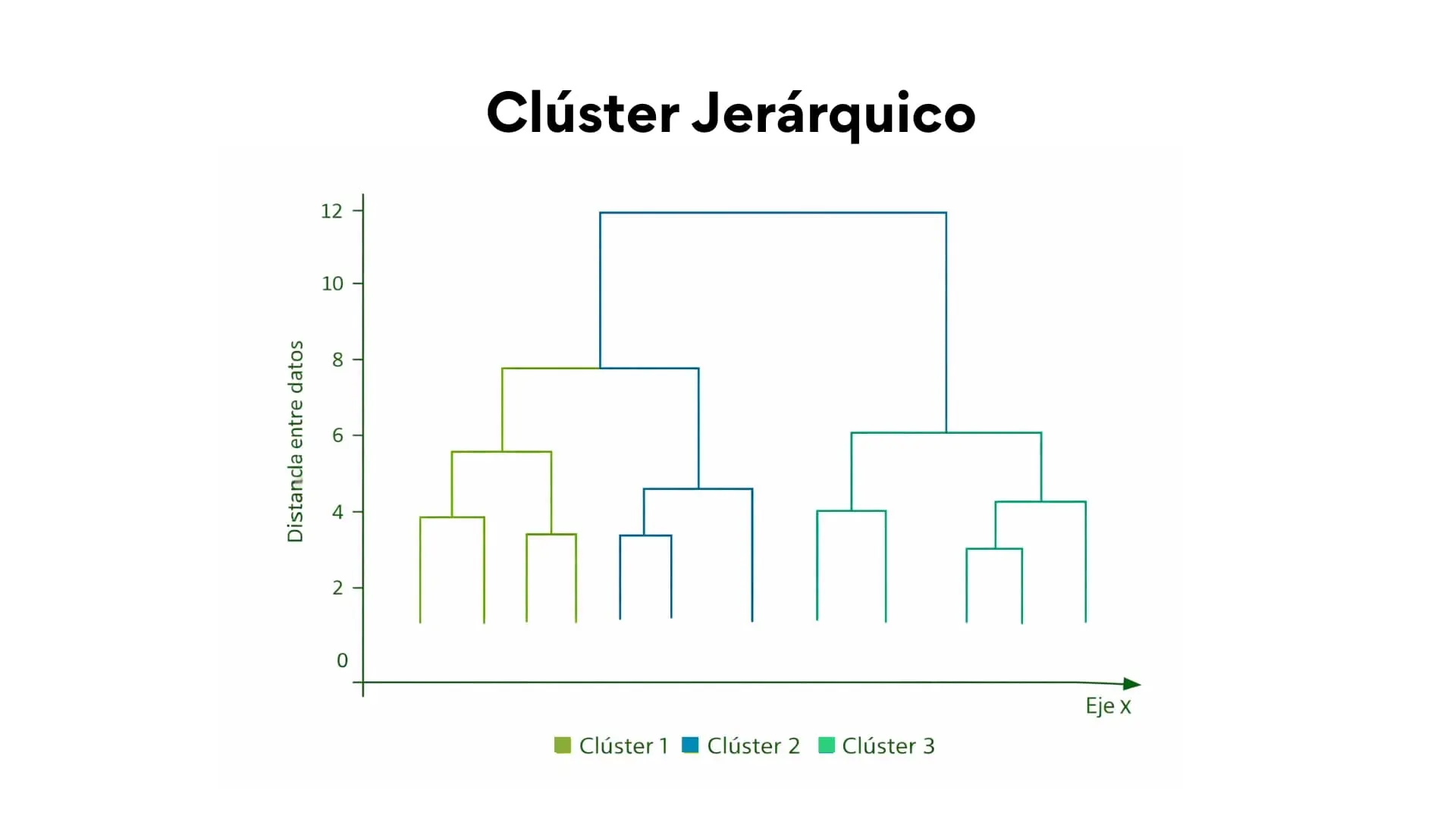
Cluster jerárquico
El clustering jerárquico es un algoritmo que busca agrupar las observaciones en conjuntos homogéneos. A diferencia del clustering de k-means, no genera una única partición final desde el principio, sino que construye una jerarquía de grupos. En su variante aglomerativa, la más común, cada observación empieza formando su propio grupo y, en cada paso, el algoritmo une los dos grupos más parecidos hasta completar toda la jerarquía. Su objetivo es lograr una alta homogeneidad intragrupo y una alta heterogeneidad entre grupos.
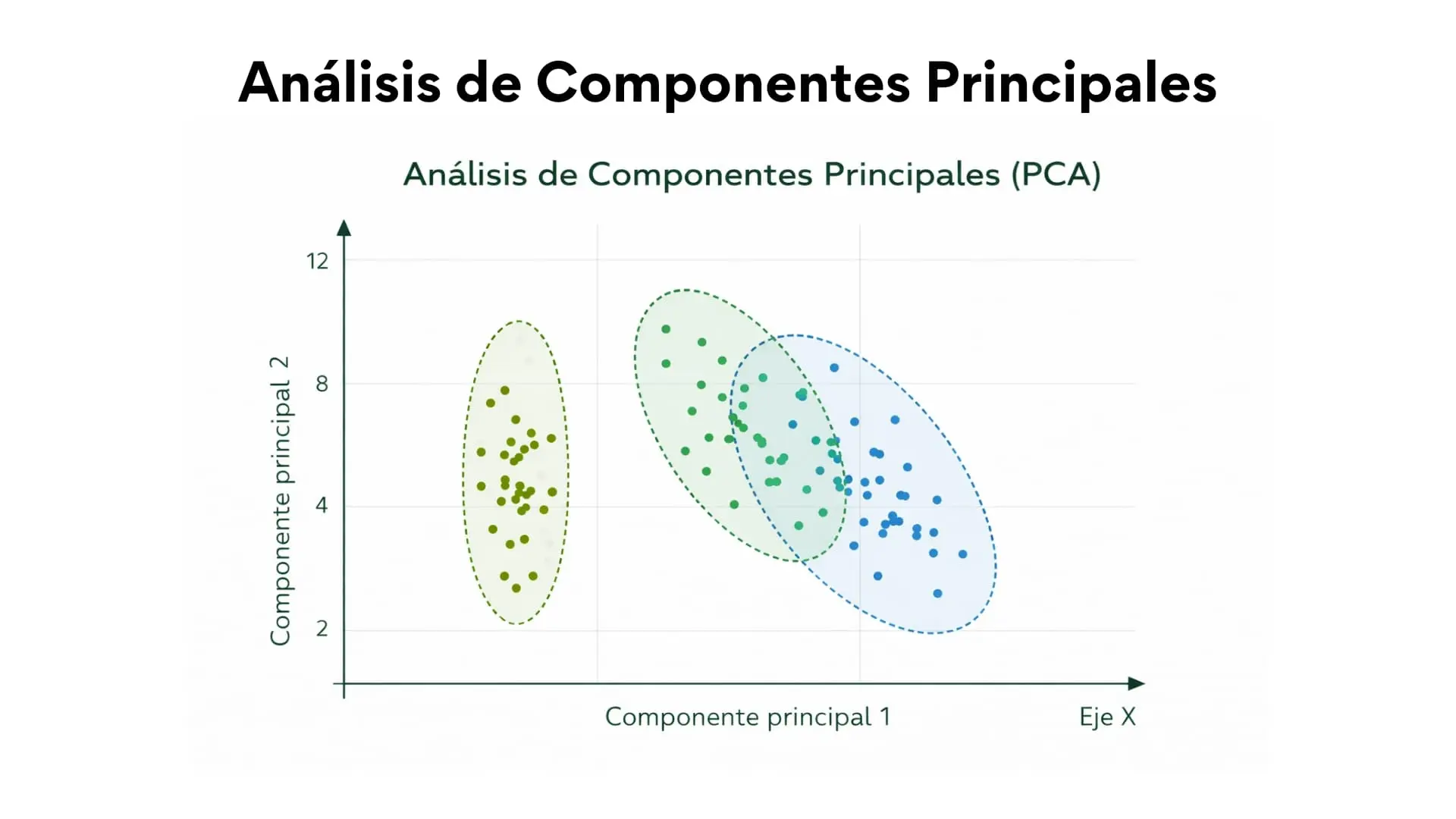
Análisis de componentes principales (PCA)
El PCA o análisis de componentes principales es una técnica estadística que se utiliza para reducir la cantidad de variables de un conjunto de datos sin perder demasiada información.
Esta técnica suele utilizarse cuando se busca agrupar un gran número de variables cuando algunas de ellas están relacionadas entre sí, de forma que esta técnica transforma estas variables en un número menor denominados componentes principales, que concentran la mayor parte de la variabilidad de los datos.
Sectores que utilizan el Machine Learning
Sector bancario
Entre las principales aplicaciones del machine learning en el sector financiero, destaca su utilidad en la concesión de préstamos, ya que permite analizar grandes volúmenes de datos y detectar patrones asociados al riesgo financiero.
De este modo, las entidades pueden estimar con mayor precisión la probabilidad de impago y apoyar la evaluación de cada cliente antes de tomar una decisión.
Máster IA en sector financiero
Sector de la salud
La IA en la salud tiene una aplicación especialmente relevanteya que permite analizar grandes volúmenes de información clínica y detectar patrones útiles para la identificación precoz de enfermedades, el apoyo al diagnóstico y la investigación médica.
Su impacto es especialmente visible en el diagnóstico por imagen, donde puede ayudar a reconocer anomalías en pruebas como radiografías, TAC o resonancias, y en áreas como los ensayos clínicos, donde contribuye a hacer más eficientes algunos procesos de evaluación y desarrollo de nuevas terapias.
Sector educativo
Uno de los ámbitos en los que el machine learning está empezando a tener una aplicación destacada es el educativo. En este contexto, pueden emplearse algoritmos entrenados con datos como calificaciones, nivel de participación o respuestas de alumnos anteriores para identificar patrones asociados a dificultades de aprendizaje o a una posible desmotivación.
La aplicación del aprendizaje automático permite al profesorado hacer un seguimiento más preciso de la evolución de cada estudiante y diseñar planes de aprendizaje más personalizados, con el fin de prevenir brechas educativas e incluso reducir el riesgo de abandono escolar por falta de motivación. Un ejemplo de ello es la IA en la enseñanza de idiomas, donde puede adaptarse el contenido al nivel del alumno, reforzar áreas de mejora y ofrecer una práctica más personalizada.
Sector de la automoción
La implementación del Machine Learning en el sector de la automoción tiene múltiples aplicaciones:
En fabricantes como BMW se entrena al software para mejorar los procesos de fabricación y detectar posibles errores en las piezas elaboradas, permitiendo mejorar la calidad de la producción y eliminar inmediatamente de la cadena aquellos componentes defectuosos.
En marcas como Volkswagen, también puede utilizarse para desarrollar sistemas de mantenimiento predictivo a partir de los datos recogidos por sensores, lo que permite anticipar posibles fallos en el vehículo.
Por otro lado, el machine learning también contribuye a mejorar la asistencia en tiempo real al conductor. En Renault han reforzado la seguridad y mejorado la experiencia de conducción de sus clientes gracias a la integración de sensores y sistemas inteligentes en los vehículos, es posible ofrecer funciones avanzadas como el mantenimiento de carril, el frenado automático, el reconocimiento de señales de tráfico o el control de crucero adaptativo.
Preguntas frecuentes
- ¿Cuál es la diferencia entre inteligencia artificial y machine learning?
La inteligencia artificial es el concepto general, mientras que el machine learning es una de sus ramas. La IA engloba sistemas capaces de realizar tareas propias de la inteligencia humana, y el machine learning se centra en que esos sistemas aprendan a partir de datos.
- ¿Chat GPT es IA o aprendizaje automático?
ChatGPT es un sistema de inteligencia artificial basado en aprendizaje automático. En concreto, funciona con modelos de lenguaje entrenados para aprender patrones a partir de grandes volúmenes de datos y generar respuestas en lenguaje natural.
Fuentes:
- Firth-Butterfield, K., & Ammanath, B. (2022, abril 4). Developing an enterprise-wide approach to machine learning. World Economic Forum. https://www.weforum.org/stories/2022/04/perfecting-the-art-of-the-whole-organisation-with-machine-learning/
- ¿Qué es el aprendizaje automático? (s/f). Google for Developers. Recuperado el 11 de marzo de 2026, de https://developers.google.com/machine-learning/intro-to-ml/what-is-ml?hl=es-419
- ¿Qué es el aprendizaje automático? Tipos y usos. (s/f). Google Cloud. Recuperado el 11 de marzo de 2026, de https://cloud.google.com/learn/what-is-machine-learning?hl=es-419
- ¿Qué es el machine learning y que usos tiene? (2024, febrero 2). CEI: Centro de Estudios e Innovación Diseño y Marketing. https://cei.es/que-es-el-machine-learning/
- Recomendaciones: ¿qué y por qué? (s/f). Google for Developers. Recuperado el 11 de marzo de 2026, de https://developers.google.com/machine-learning/recommendation/overview?hl=es-419
- Barnard, J., & Stryker, C. (2025, diciembre 2). ¿Qué es la detección de anomalías? Ibm.com. https://www.ibm.com/es-es/think/topics/anomaly-detection